Mneme began with frustration. I'd been experimenting with AI for content generation, and every approach hit the same walls: cloud APIs were expensive and metered by the token, my data left my control the moment I hit "send," services went down when I needed them most, and models forgot everything I taught them yesterday.
I wanted something different. AI that ran on my hardware, learned from my feedback, cost what I chose to spend on equipment rather than subscription fees, and stayed available whether the internet was up or down. Not because I'm a purist, but because I believe the future of AI will include more diverse, specialized, and distributed models.
That frustration became Mneme's foundation: local-first AI with specialized personas that learn and improve over time.
Why Local-First: Privacy, Control, and a Different Vision
Running models locally wasn't just a technical choice-it was philosophical. Here's why it mattered:
Privacy Without Compromise
When you send content to a cloud API, you're trusting that provider with your ideas, drafts, business strategies, and personal data. For educational content, e-books, or internal tools, that trust isn't always warranted. Local execution means sensitive data never leaves your network. No terms of service changes, no "we'll use your data to improve our models," no third-party access.
Cost and Control
Cloud APIs are convenient until you scale. A few hundred e-book generations or thousands of tutorial images, and you're looking at substantial monthly bills with unpredictable spikes. Local models have upfront hardware costs, but once you own the GPU, inference is "free"-you control the budget, the throttling, and the priorities. When I want to generate 50 variations of an image at 2 AM, I don't check my API balance first.
Availability and Resilience
Cloud services go down. APIs hit rate limits. Providers deprecate models or change pricing. Local infrastructure keeps working during internet outages, doesn't care about your request volume, and won't disappear because a company pivoted strategy. Resilience isn't just uptime-it's sovereignty over your tools.
Mneme is my answer: proof that local-first, specialized AI is viable, practical, and powerful enough to ship real products.
The Hardware Journey: From M1 to M4 Max to RTX 4080
I started with what I had: an M1 MacBook Pro with 32GB of unified memory. It worked-sort of. Generating a full e-book outline took 30 minutes. A batch of tutorial images? Forget it. The M1 proved the concept, but it couldn't scale.
When I committed to Mneme as a production platform, I upgraded to an M4 Max Mac Studio with 128GB unified RAM. Suddenly, I could run multiple models simultaneously: a 27B parameter model for planning while a vision model validated images in the background. Workflows that took hours now took minutes. The hardware became invisible-it just worked.
But images and music needed GPU horsepower the Mac couldn't deliver. I repurposed a gaming PC with an RTX 4080 (16GB VRAM) running Windows as the "media factory." ComfyUI for images, Stable Audio for music, all networked to the Mac Studio. This wasn't over-engineering; it was learning which constraints actually mattered. The M4 Max handles orchestration and LLM inference. The RTX 4080 handles pixels and waveforms. The M1 MacBook? Still in the bag for on-the-road updates.
• Apple M4 Max Mac Studio (128GB RAM): Main development platform, LLM inference (Gemma 27B, llava:34b), orchestration, database
• PC with RTX 4080 16GB (Windows): ComfyUI image generation, Stable Audio music synthesis, isolated from main workflow
• Apple M1 MacBook Pro (32GB RAM): Mobile development, testing, on-the-road updates
This tiered approach-modest local for fast decisions, powerful local for deep work, cloud only when justified-became Mneme's operating principle.
The Core Stack: FastAPI, MongoDB, and WebSockets
Mneme needed to feel alive during long-running jobs-not a black box that might or might not be working. That requirement shaped the technical stack:
- FastAPI: Async-first web framework for APIs and WebSocket endpoints. Handles concurrent workflows cleanly.
- MongoDB: Flexible document storage for projects, personas, prompts, feedback, and artifacts. Schema evolution without migrations.
- Tailwind CSS + Jinja2: Minimal UI that surfaces real-time progress without JavaScript framework overhead.
- WebSockets: Live updates during generation-streaming LLM output, image progress, validation results, token counts, phase transitions.
This stack isn't flashy, but it's reliable. When an e-book generation runs for 40 minutes, users see every phase: researching sources, drafting outline, generating chapters, validating structure, creating artifacts. Progress isn't a spinner-it's detailed, real-time feedback.
Role-Based Multi-LLM Router: Right Model, Right Task
Not all tasks need a frontier model. Mneme routes work based on cognitive role, not "biggest model available." This keeps costs low, latency reasonable, and specialization high.
• local_llm: Fast decisions, planning, glue logic (Gemma 27B via llama.cpp on M4 Max, ~20 tokens/sec)
• research_llm: Deep research, analysis, synthesis (Gemma 27B or larger via Ollama)
• ponder_llm: Reflection, quality assessment, iterative refinement (20B+ local model)
• image_llm: Vision tasks, image validation, description (llava:34b via Ollama, multimodal)
• code_llm: Code generation, debugging, validation (qwen-coder:30b via Ollama)
The router tracks model health, token usage, and queue depth. It supports streaming for real-time output and integrates LoRA adapters for persona-specific behavior. This design makes Mneme flexible: swap a model, update a route, adjust temperature-without rewriting orchestrators.
Concrete Example: Tutorial Generation Workflow
When a user requests a tutorial on "Proper Shoulder Press Form," here's how the multi-LLM router orchestrates the work:
1. User Request: "Create tutorial: Proper Shoulder Press Form"
→ local_llm (planning): Analyze request, create project outline
2. Research Phase
→ research_llm: "Gather authoritative sources on shoulder press biomechanics"
→ Output: 5 key sources, safety considerations, common mistakes
3. Content Drafting
→ local_llm: Generate tutorial structure (intro, steps, tips, summary)
→ research_llm: Expand each step with biomechanical details
4. Image Generation
→ local_llm: Draft image prompts ("start position," "finish position")
→ Picaso persona + ComfyUI: Generate tutorial diagrams
→ image_llm (llava:34b): Validate images against requirements
5. Validation
→ ponder_llm: Review tutorial for clarity, completeness, safety warnings
→ Feedback: "Add warning about shoulder mobility limitations"
6. Revision
→ local_llm: Incorporate feedback, regenerate affected sections
7. Publishing
→ Pandoc (via MCP): Convert to HTML, PDF
→ Artifacts saved, user notifiedEach role does what it's optimized for. The fast local model coordinates; the research model goes deep; the vision model validates images. Total cost: $0 in API fees. Total time: ~8 minutes. All local.
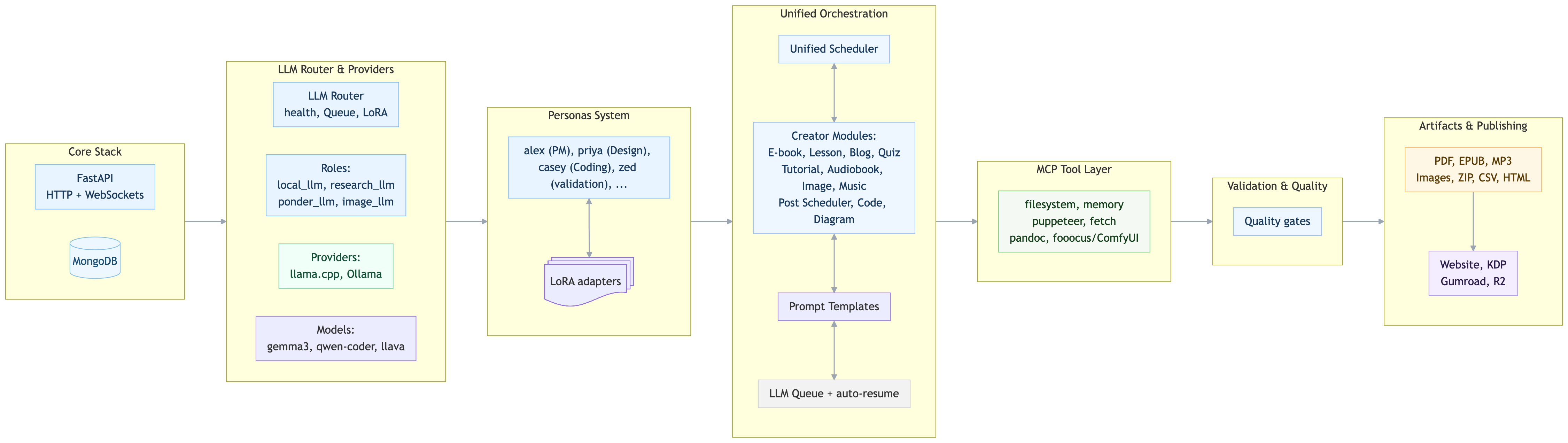
Personas with LoRA Lineage: Learning That Sticks
This is where Mneme diverges from "prompt engineering." Personas aren't just clever prompts-they're capabilities with version history and measurable improvement over time.
Each persona (casey the coder, priya the architect, picaso the image prompter, zed the validator) maintains a LoRA lineage: small, targeted adapter weights trained on curated feedback. When users mark an output as "good" or "needs work," that signal feeds the training pipeline. At night, Mneme's "dreaming" process consolidates feedback, generates training pairs, and fine-tunes LoRA adapters.
V1 (baseline) → generic structure, surface-level examples ↓ Training on 20 "bad vs. good" pairs V2 → better structure, fewer generic paragraphs ↓ Training on examples, pitfalls, checklists V3 → consistent use of examples + pitfalls per chapter ↓ Training on tone coherence, diagram cues V4 → current production version
This isn't theoretical. When I upgraded the E-book persona from V2 to V3, the first-draft acceptance rate went from 40% to 75%. The persona learned what "good" looked like and started producing it by default. Rollback is trivial-if V4 regresses, revert to V3. The lineage is preserved, versioned, and auditable.
MCP: Bridging Thinking and Doing
LLMs can reason, plan, and generate-but they can't save files, convert documents, or click buttons. The Model Context Protocol (MCP) closes that gap, turning Mneme's personas from "thinkers" into "doers."
Mneme's MCP layer provides standardized tools that any persona can invoke:
- Filesystem: Read, write, search, edit files within project-scoped sandboxes
- Fetch + Browser: Retrieve web content, navigate pages, fill forms, take screenshots (via Playwright)
- ComfyUI + Fooocus: Queue image/music generation workflows, poll status, retrieve artifacts
- Pandoc: Convert between formats (Markdown → EPUB, PDF, HTML)
- Exec/Bash: Run sandboxed shell commands for preprocessing, validation, packaging
This architecture means the same persona logic works whether we're generating an e-book (Pandoc), a tutorial image (ComfyUI), or validating code (filesystem + exec). No bespoke per-module plumbing-just composable tools behind a stable interface.
pandoc_server.convert(markdown, "epub") via MCP. The persona doesn't know how Pandoc works-it just knows the tool exists and what parameters it needs. Swap Pandoc for a different converter? Update the MCP server, not the persona.
The Creator Module Pattern: Reusable Spine
After building E-book Creator and Audiobook Creator separately, I noticed they shared the same skeleton: Topic → Project → Workflow (multi-phase) → Validation → Artifacts → Publishing. That pattern became the template for every module.
UnifiedProjectScheduler (heartbeat every N minutes)
→ ProjectHandler (ebook | tutorial | blog | image | music | code)
→ find_pending_work() → List[WorkItem]
→ ProjectDispatcher.dispatch(work_item)
→ {Module}Orchestrator.process_workflow()
→ Phase 1: Research/Plan
→ Phase 2: Generate/Draft
→ Phase 3: Validate
→ Phase 4: Revise (if needed)
→ Phase 5: Package Artifacts
→ Phase 6: Publish/NotifyThis made adding new modules-Image Creator, Music Creator, Code Creator-a matter of implementing the handler interface and orchestrator phases. The scheduler, retry logic, checkpoints, WebSocket progress, and artifact storage? Already there. Reuse the spine; specialize the muscles.
The "Aha" Moment: When It All Clicked
Three months into building Mneme, I had a realization. I'd just added Image Creator as the fifth module, and it took two days-not two weeks. Why? Because I wasn't building five separate systems anymore. I was composing known parts: role-based LLM routing, MCP tool bridges, persona prompts, validation gates, artifact pipelines. The architecture had become a platform.
The moment that solidified it: I wanted to add vision-based validation to Comic Creator (using llava:34b to check if generated panels matched requirements). I added image_llm to the router, wrote a 30-line validation function, and it worked on the first try. No refactoring, no "special case for vision models," no architectural gymnastics. The system was ready because the patterns were right.
That's when I knew Mneme wasn't just a content generator-it was a proof that local-first, persona-driven, tool-augmented AI could scale.
What I'd Keep / What I'd Change
- Keep: Local-first philosophy, role-based LLM routing, persona LoRA lineage, MCP abstraction, creator module pattern, WebSocket observability everywhere
- Change: Adopt test-first + reflection loops earlier in Code Creator; build an agentic browser tester (vision-based computer-use agent) for E2E UI validation; add deeper cost/energy tracking per workflow to optimize hardware usage
Why This Matters Beyond Mneme
Mneme is one system, but the principles generalize. Local-first AI isn't just viable-it's necessary for a fairer future. Privacy, cost control, availability, and resilience shouldn't be luxuries reserved for those who can afford enterprise cloud contracts. Specialized personas learning from feedback shouldn't require retraining billion-parameter models from scratch.
The alternative is relying on a single intelligent model may create systemic fragility. Nature shows us a better way: evolution through diversity, specialization, and distributed learning. Mneme is my attempt to build toward that vision, one specialized persona at a time.
In the posts that follow, I'll break down how each module works, what failed along the way, and what I learned building a production AI platform on consumer hardware. But it all starts here: with the decision to go local, to diversify instead of centralize, and to prove that another path is possible.